In a previous post, I explained that a BioPAX document is really an RDF graph. And with that in mind, you can do interesting things like inferring identifiers.org URI’s using a SPARQL CONSTRUCT query.
What I didn’t explain is that, after adding those new inferences, the result is no longer valid BioPAX. RDF gives you lots of freedom, as well as lots of rope to hang yourself with. BioPAX has some restrictions in place that are necessary for exchange of pathway data.
Let me explain in more detail. Take a look at the BioPAX snippet below. This snippet represents more or less the same information as the first figure from my previous post. It represents Protein186961, with a bp:xref property pointing to id4, which is a UnificationXref with bp:db property FlyBase and bp:id property FBgn0034356.
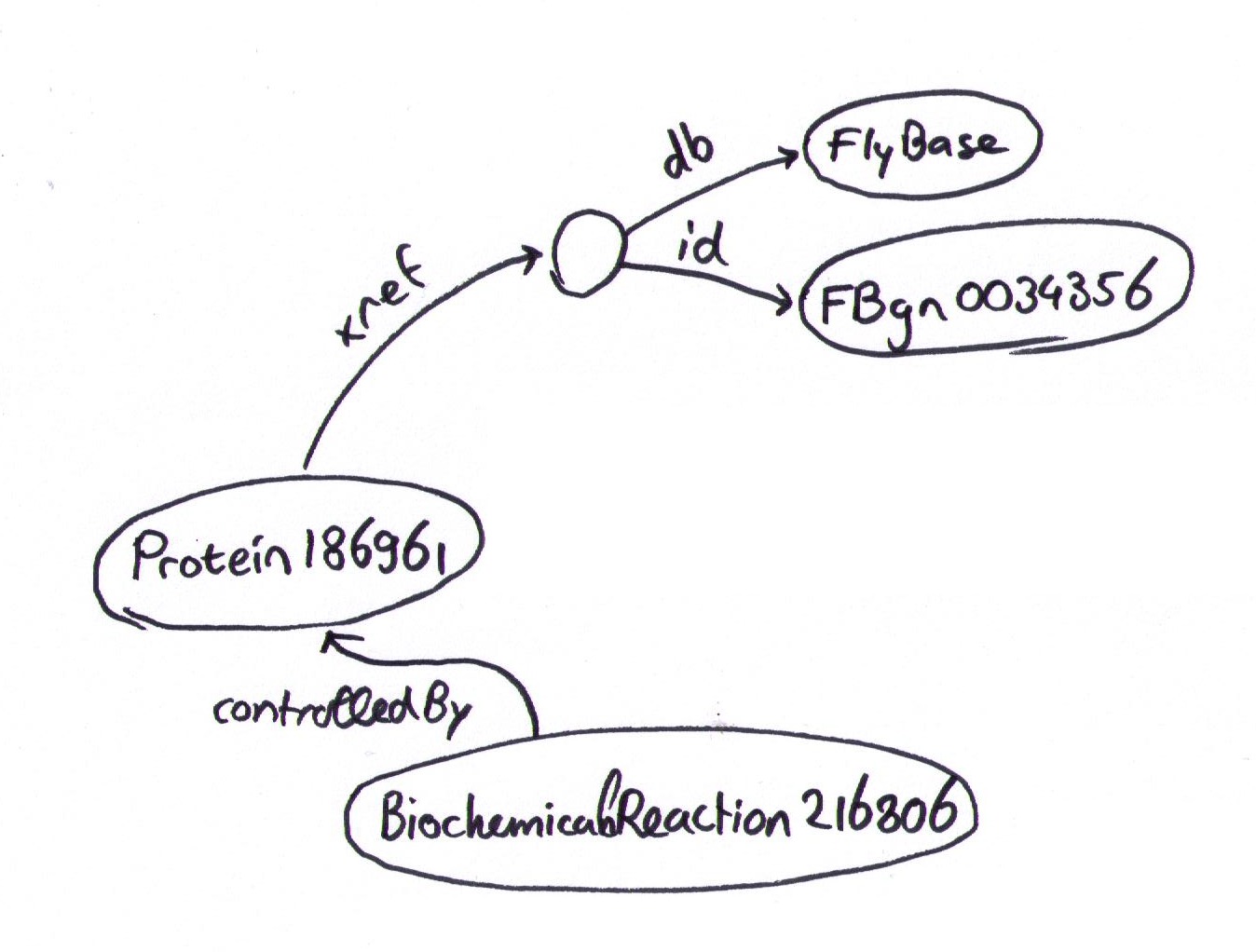{kind=link}
<bp:xref rdf:resource="id4" />
</bp:ProteinReference>
<bp:UnificationXref rdf:about="id4">
<bp:id rdf:datatype="xsd:string">FBgn0034356</bp:id>
<bp:db rdf:datatype="xsd:string">FlyBase</bp:db>
</bp:UnificationXref>
After the SPARQL CONSTRUCT query, the newly inferred URI’s are added back to the graph. The results looks more or less like this:
<bp:xref rdf:resource="id4" />
<bp:xref rdf:resource="http://identifiers.org/flybase/FBgn0034356"/>
</bp:ProteinReference>
As you can see, Protein186961 now has two bp:xref properties. This kind of duplication may cause problems for software. Furthermore, the new bp:xref property doesn’t have the correct type (UnificationXref), and it doesn’t have values for bp:db and bp:id, because our CONSTRUCT query didn’t say anything about them. Yet well-behaving pathway software might quite reasonably be looking for that information.
Running inferences on an RDF store gives you lots of power, but it’s not necessarily good for standardization. If you are running a large pathway database, you might want to enforce some restrictions. The online BioPAX validator created by Igor Rodchenkov et al. is the gold standard for producing correct, manageable BioPAX. Running it on the second snippet leads to this error:

But what if you want to have Identifiers.org URI’s, but you also want to keep your BioPAX valid? It’s easy – the UnificationXref in the first snippet used id4 as resource identifier. Id4 is just an arbitrary value – we can easily replace that with something better. But instead of running a construct query, it’s a matter of modifying your BioPAX generating code to write out identifiers.org URI’s where possible. The result could look like the snippet below. Admittedly, the result has a bit of redundancy, with the two references to FBgn0034356. But that is a small price to pay. The new version has identifiers.org goodness ready for SPARQL integration magic, yet it’s still standard compliant so that mundane software can cope with it too.
<bp:xref rdf:resource="http://identifiers.org/flybase/FBgn0034356" />
</bp:ProteinReference>
<bp:UnificationXref rdf:about="http://identifiers.org/flybase/FBgn0034356">
<bp:id rdf:datatype="xsd:string">FBgn0034356</bp:id>
<bp:db rdf:datatype="xsd:string">FlyBase</bp:db>
</bp:UnificationXref>
Tags: biopax, identifiers
Hi Martijn,
This is an interesting post. Michel Dumontier suggests using reification to handle this:
http://www.slideshare.net/micheldumontier/biopax-models-and-pathways
I’m looking at how to use Biopax with GO terms, and it appears the Biopax for a Gene could correctly put GO terms under either of these:
bp:UnificationXref
bp:DnaReference
bp:cellularLocation
and either of these for a protein:
bp:cellularLocation
bp:RelationshipXref
Would you suggest duplicating a GO term under both bp:cellularLocation and bp:RelationshipXref, or just specifying it once?
I would suggest using cellular location only for the GO terms that fall in the Cellular location hierarchy, and Unification Xref for GO terms that fall in the molecular function and biological process hierarchies.
At my consulting job, we’re moving more and more in that direction: use more specific predicates than just “xref”: for example “x-go-bp”, “x-ensembl-gene”, “x-uniprot”. Doing so helps write more efficient queries. It is also the approach advocated in the presentation you linked (slide 22: use more specific predicates). Unfortunately within the realm of biopax, there isn’t room for creating new predicates, you have to deal with what exists.